Correos Electrónicos: Una Mirada Profunda a la Aplicación Práctica de Naive Bayes en Aprendizaje Supervisado
 |
Correos Electrónicos: Una Mirada Profunda a la Aplicación Práctica de Naive Bayes en Aprendizaje Supervisado |
Introducción:
En el vasto océano de datos, la clasificación efectiva es esencial. Naive Bayes, basado en el teorema de Bayes, se presenta como un faro de eficacia en el aprendizaje supervisado. En esta entrada, exploraremos el teorema de Bayes y cómo la simplicidad del enfoque "Naive" puede ser extraordinariamente útil, especialmente en la clasificación de spam en correos electrónicos.
Contextualización:
Desde su formulación por el estadístico y teólogo británico Thomas Bayes en el siglo XVIII hasta su aplicación moderna en el aprendizaje automático, el teorema de Bayes ha demostrado ser un marco robusto para la inferencia probabilística. Naive Bayes, con sus suposiciones simplificadas, destaca por su eficiencia computacional y ha encontrado aplicaciones en diversas áreas.
Desarrollo:
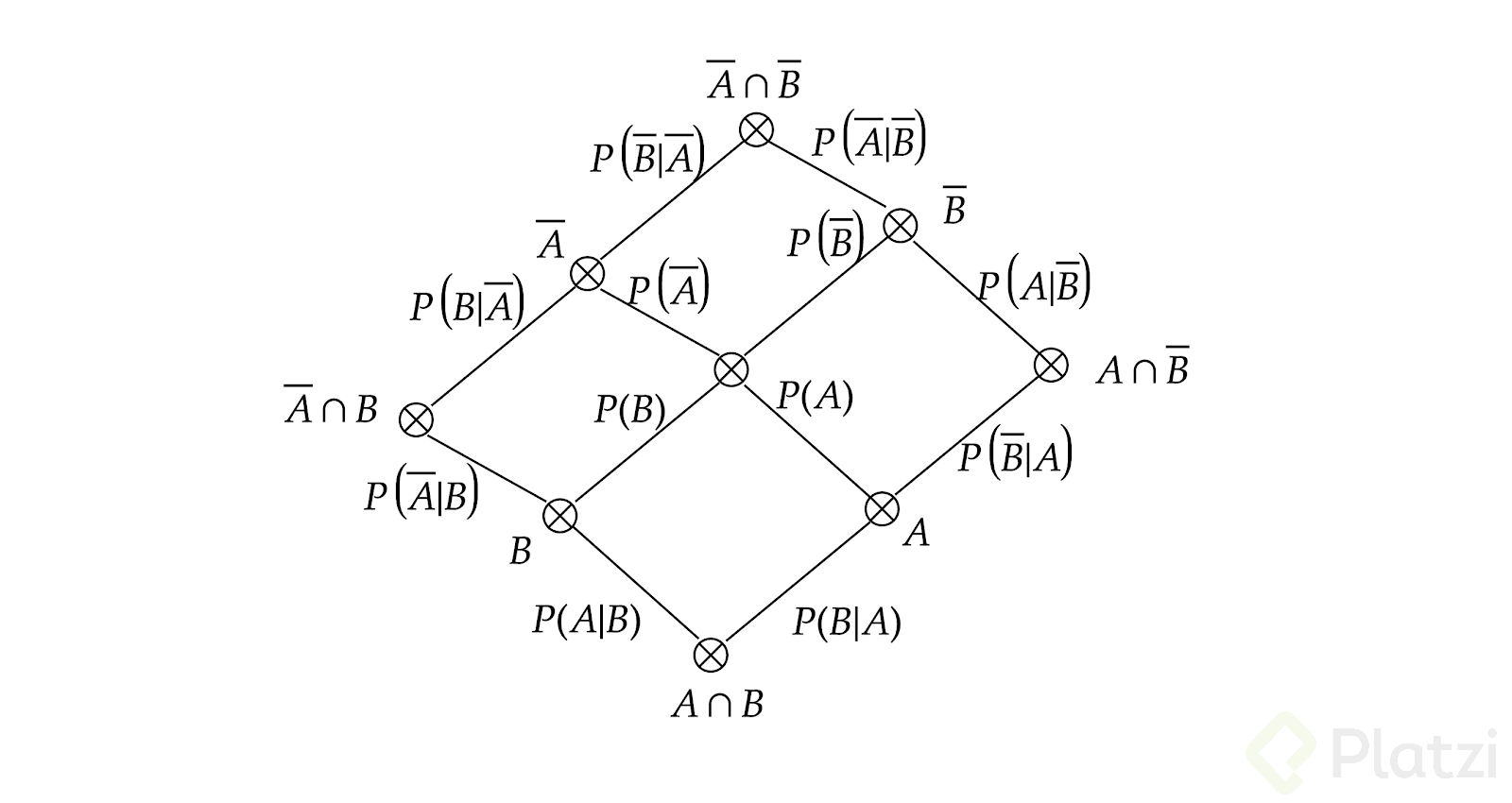
Introducción al Teorema de Bayes y el Enfoque "Naive":
El teorema de Bayes es la base para entender la probabilidad condicional. El enfoque "Naive" asume independencia entre las características, simplificando el cálculo de probabilidades.
Aplicación en el Filtrado de Spam en Correos Electrónicos:
Supongamos que queremos filtrar correos electrónicos como spam o no spam. Utilizaremos datos ficticios para entrenar nuestro modelo Naive Bayes.
# Código para la aplicación de Naive Bayes en el filtrado de spam
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# Generación de datos ficticios
data = {'mensaje': ['¡Oferta imperdible! Gana dinero fácil y rápido.',
'Reunión de trabajo mañana a las 10 AM.',
'Descubre las últimas tendencias en energía renovable.']}
labels = [1, 0, 0] # 1 para spam, 0 para no spam
df = pd.DataFrame(data)
# Creación de características mediante CountVectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(df['mensaje'])
# División del conjunto de datos
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.2, random_state=42)
# Entrenamiento del modelo Naive Bayes
model = MultinomialNB()
model.fit(X_train, y_train)
# Predicciones
y_pred = model.predict(X_test)
# Evaluación del modelo
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
class_report = classification_report(y_test, y_pred)
print(f'Precisión del modelo: {accuracy}')
print(f'Matriz de Confusión:\n{conf_matrix}\n')
print(f'Reporte de Clasificación:\n{class_report}')
Este código simula la clasificación de mensajes de correo electrónico como spam o no spam utilizando Naive Bayes.
Discusión sobre Suposiciones y Limitaciones del Modelo:
Exploramos las suposiciones detrás del modelo Naive Bayes, como la independencia de características, y discutimos sus limitaciones en situaciones donde estas suposiciones no se cumplen.
Perspectivas y Tendencias:
Las perspectivas futuras de Naive Bayes incluyen adaptaciones para lidiar con la dependencia entre características, así como su integración en sistemas más complejos de aprendizaje automático.
Conclusiones:
Naive Bayes es una herramienta eficiente y efectiva en la clasificación, especialmente en problemas de texto como el filtrado de spam.
- La simplicidad del enfoque "Naive" permite un rendimiento computacionalmente eficiente.
- Aunque poderoso, Naive Bayes tiene limitaciones en situaciones donde las características no son independientes.
Reflexiones:
¿Cómo podrías aplicar Naive Bayes en tu entorno laboral o proyecto personal? Reflexiona sobre cómo
Comentarios
Publicar un comentario